FingerVision
 フィンガービジョン (FingerVision) はロボットフィンガ用に開発された,ビジョンベースの接触センサ(オプティカルスキン)です.フィンガービジョンはマルチモーダルで(接触力分布,近接ビジョン:すべり・変形・物体姿勢推定),簡単に作れて,物理的に頑丈であり,かつ安価(材料費は$50程度)という特徴を持ちます.
→プロジェクトのウェブサイト
フィンガービジョン (FingerVision) はロボットフィンガ用に開発された,ビジョンベースの接触センサ(オプティカルスキン)です.フィンガービジョンはマルチモーダルで(接触力分布,近接ビジョン:すべり・変形・物体姿勢推定),簡単に作れて,物理的に頑丈であり,かつ安価(材料費は$50程度)という特徴を持ちます.
→プロジェクトのウェブサイト
「注ぐ」動作の模倣学習
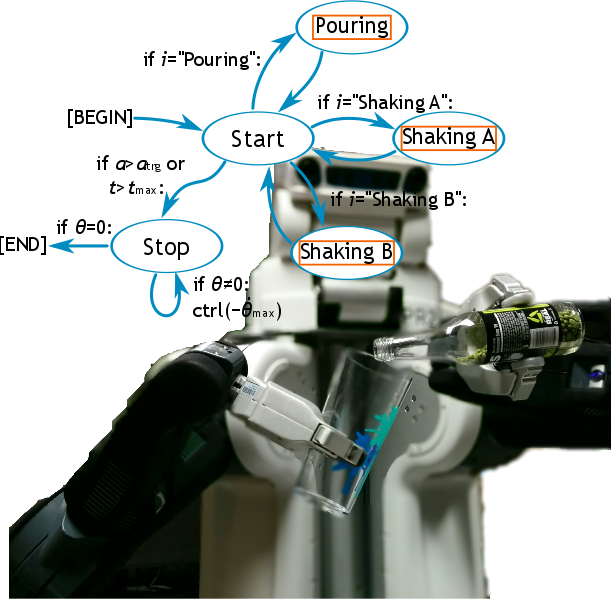 模倣学習の枠組みで「注ぐ」動作について研究しています.
この研究のゴールは,多くの形態を持つ複雑なタスクをどのように表現し,計画し,学習するかを探ることです.
..続き
模倣学習の枠組みで「注ぐ」動作について研究しています.
この研究のゴールは,多くの形態を持つ複雑なタスクをどのように表現し,計画し,学習するかを探ることです.
..続き
学習戦略フュージョン
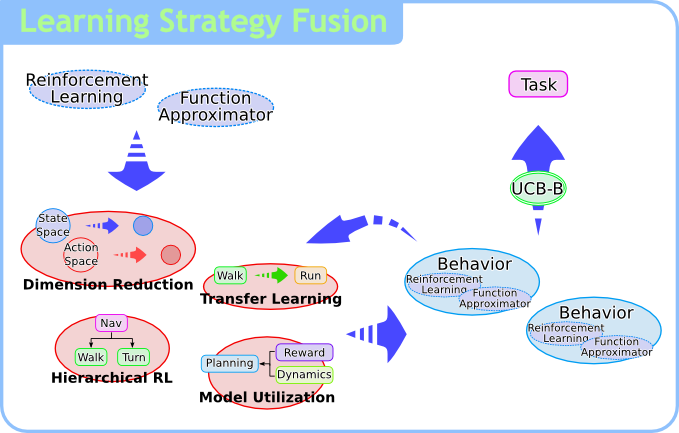 学習戦略フュージョンは,強化学習の枠組で学習戦略群を融合する手法です.
一般的に,それぞれのタスクに対して適切な学習戦略を選ぶ必要があります.
一方,提案手法は学習戦略を融合することにより,この選択を自動化します.
..続き
学習戦略フュージョンは,強化学習の枠組で学習戦略群を融合する手法です.
一般的に,それぞれのタスクに対して適切な学習戦略を選ぶ必要があります.
一方,提案手法は学習戦略を融合することにより,この選択を自動化します.
..続き
SkyAI: 高度にモジュール化された強化学習ライブラリ
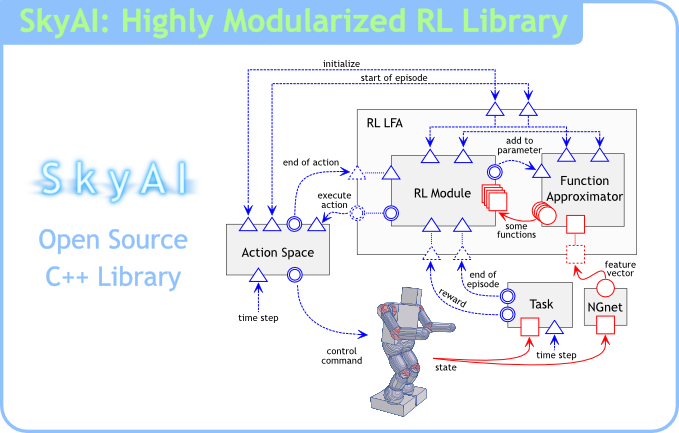 SkyAI は強化学習の手法群を収録したオープンソースのソフトウェアライブラリです.
SkyAI の特徴は,高い実行速度と学習システムの柔軟な構築を実現するモジュール構造にあります.
..続き
SkyAI は強化学習の手法群を収録したオープンソースのソフトウェアライブラリです.
SkyAI の特徴は,高い実行速度と学習システムの柔軟な構築を実現するモジュール構造にあります.
..続き
DCOB: 高自由度ロボットの運動学習ための行動空間
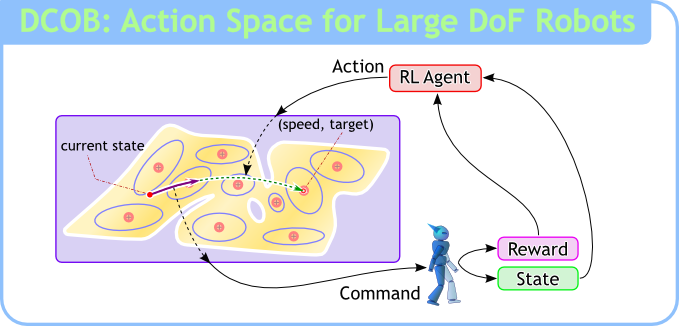 DCOB は価値関数を近似するために与えられた基底関数の集合から離散行動空間を生成する手法です.
規模の大きい問題に適用できることが最大の特徴です.
..続き
DCOB は価値関数を近似するために与えられた基底関数の集合から離散行動空間を生成する手法です.
規模の大きい問題に適用できることが最大の特徴です.
..続き

ヒューマノイドの歩行学習
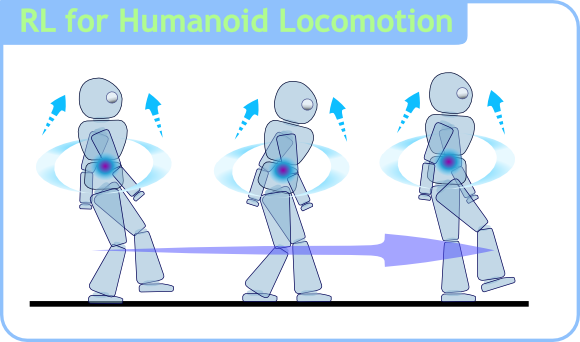 この研究では,私たちが開発した強化学習手法を等身大のヒューマノイドロボットの歩行学習に適用しています.
ここでは,学習中にバランスコントローラを駆動するという,新しい歩行学習の枠組が研究されています.
..続き
この研究では,私たちが開発した強化学習手法を等身大のヒューマノイドロボットの歩行学習に適用しています.
ここでは,学習中にバランスコントローラを駆動するという,新しい歩行学習の枠組が研究されています.
..続き
モデルの分離学習
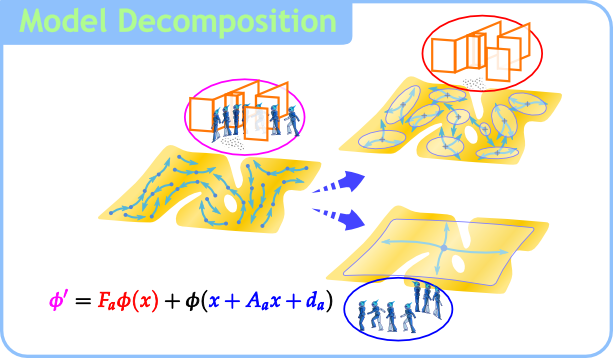 この研究では,ダイナミクスモデルをタスク固有の要素とタスク不変の要素に分解する手法を開発しました.
この手法により,あるタスクで学習したダイナミクスモデルをほかのタスクのモデルに転移することが可能となります.
..続き
この研究では,ダイナミクスモデルをタスク固有の要素とタスク不変の要素に分解する手法を開発しました.
この手法により,あるタスクで学習したダイナミクスモデルをほかのタスクのモデルに転移することが可能となります.
..続き
DQL+: 危険な行動の記憶の再利用
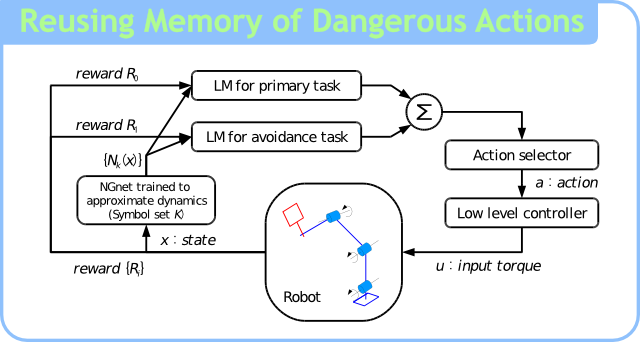 DQL+ は行動価値関数を2つに分離する手法で,一方の価値関数が危険な行動(例えば転倒につながる行動)を学習します.
危険な行動の記憶は,タスクに対して不変であると考えられます.つまり,DQL+ を用いることにより,タスク間で記憶を共有できるようになります.
..続き
DQL+ は行動価値関数を2つに分離する手法で,一方の価値関数が危険な行動(例えば転倒につながる行動)を学習します.
危険な行動の記憶は,タスクに対して不変であると考えられます.つまり,DQL+ を用いることにより,タスク間で記憶を共有できるようになります.
..続き