DQL+: 危険な行動の記憶の再利用
新しい動作を学習するとき,私たち人間は,既に学習した記憶を再利用しています.特に,危険な行動の記憶は優先的に再利用されるはずです.例えば,転倒につながるような行動は記憶され,新しい動作の学習において再利用されるべきです.
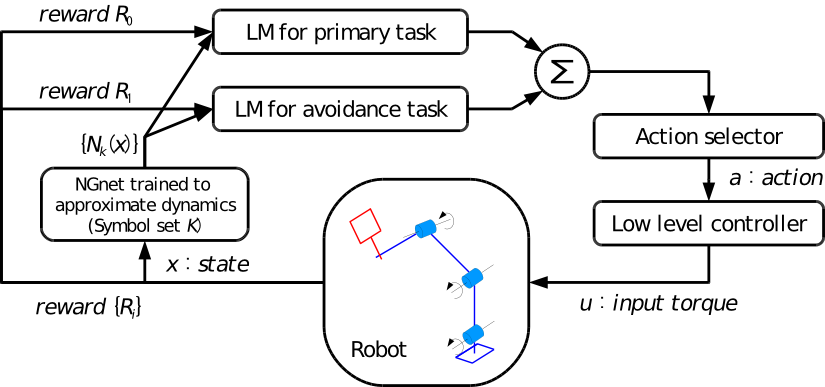
この研究のねらいは,危険な行動を記憶し,再利用するアーキテクチャの開発です.提案手法は強化学習の枠組の上で開発され,"Decomposed Q-Learning+" を意味する DQL+ と名付けられました.DQL+ は一種の,行動価値関数の分離学習です.つまり,いくつかのサブ行動価値関数が分離して学習されます.これらのうちのひとつが危険な行動を記憶し,将来の学習において再利用されるのです.
分離学習の先行研究が,Russell らによって提案されていました [ICML 2003].DQL+ の利点は,サブ行動価値関数の再利用により適しているということです.下の動画は,テニスサーブの学習において,危険な行動(転倒)の記憶を再利用する場合の DQL+ の利点を可視化したものです.
左は DQL+,右は Russell らの手法です.いずれの手法も,(テニスサーブの学習タスクよりも前に)危険な行動を記憶させておいたサブ行動価値関数を再利用しています.それぞれの左下のバーは累積ダメージを表しています.
ご覧のように,ダメージバーの増加速度は DQL+ の方が Russell らの手法よりも遅いです.これは,DQL+ が Russell らの手法よりも効果的に危険な行動の記憶を再利用できているからだと考えられます.
関連論文
- 山口 明彦, 杉本 徳和, 川人 光男:
回避行動の再利用メカニズムを備えた強化学習手法と多関節ロボットの全身運動学習への応用,
日本ロボット学会誌, Vol.27, No.2, pp.209-220, 2009. [PDF] - 山口 明彦, 杉本 徳和, 川人 光男:
回避行動の再利用メカニズムを備えた強化学習のための関数近似器修正手法と多関節ロボットへの応用,
電子情報通信学会技術研究報告, Vol.107, No.410, pp.87-92, 愛知, 2007年12月. [CiNii] [final-draft] - 山口 明彦, 杉本 徳和, 川人 光男:
回避行動の再利用メカニズムを持つ強化学習手法の提案と多関節ロボットへの応用,
第25回日本ロボット学会学術講演会, 3N37, 千葉, 2007年9月. [PDF]