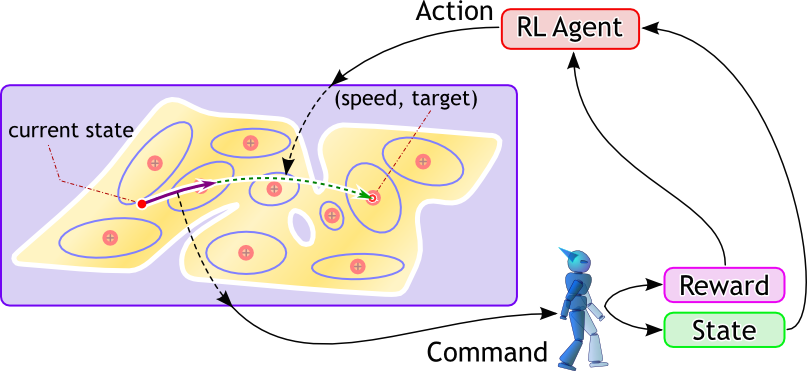
DCOB: 高自由度ロボットの運動学習ための行動空間
強化学習手法は,報酬(目的)関数によって表現された目的のみから,ロボットが自律的に行動を獲得することを可能にします.しかしながら,ヒューマノイドのような高次元の制御入力空間への対処は,未解決問題のひとつです.
この研究のねらいは,ロボットが高速に高パフォーマンスな動作を学習できる,強化学習手法にとって最適な行動空間を開発することです.
私たちは,DCOBという離散行動集合を提案しました.DCOB は "an action Directed to the Center Of a Basis function"(基底関数の中心に向かう行動)を意味します.DCOB は価値関数を近似するために与えられた基底関数の集合から生成されます.DCOB は離散集合ですが,高いパフォーマンスの動作を獲得できます.
DCOB の拡張として,WF-DCOB を提案しました.WF-DCOB は wire-fitting と呼ばれる手法を用いて,DCOB が離散化する前の連続空間で直接学習を行う手法です.このように,WF-DCOB は DCOB よりも高いパフォーマンスを得る能力を持っています.しかし,wire-fitting の学習の不安定さのため,今までのところ,DCOB と同程度のパフォーマンスしか達成できていません.
ロボットの運動学習への適用
跳躍の学習
シミュレーション上のヒューマノイドロボットの跳躍タスクに DCOB を適用しました.強化学習手法としては,Peng の Q(λ)-learning を用いました.
学習の初期段階では,ロボットはランダムに振る舞います.これは,スクラッチ(事前知識を与えない)から学習したからです.
学習後,ロボットは跳躍を獲得できました.
匍匐(ほふく)の学習
DCOB はさまざまな動作に適用可能です.次は,匍匐動作への適用例です.
学習の初期段階では,ロボットの振る舞いは跳躍の場合とほとんど同じです.これは,やはりスクラッチから学習しているからです.
学習後,ロボットは匍匐の獲得に成功しました.
実ロボットの匍匐
シミュレーションだけ? そんなことはありません! 私たちの手法は実ロボットへも適用可能です. DCOB を実機のクモ型ロボット(ROBOTIS社製のBioloid)の匍匐学習に適用しました.
この動画は学習段階です.ロボットは同様にスクラッチから学習します(シミュレーションは行っていません!).
学習後,ロボットは匍匐の獲得に成功しました(約30分ほどです).
ほかの視点から:
AURO2013用動画
実装
DCOB は SkyAI 上に実装されています.今すぐテストしてみてください!
関連論文
- Akihiko Yamaguchi, Jun Takamatsu, and Tsukasa Ogasawara:
DCOB: Action space for reinforcement learning of high DoF robots,
Autonomous Robots, Vol.34, No.4, pp.327-346, May, 2013. [PDF] [Springer] [Video] - 山口 明彦, 高松 淳, 小笠原 司:
強化学習によるロボットの動作獲得のための基底関数に基づく行動空間生成手法,
日本ロボット学会誌, Vol.29, No.1, pp.55-66, 2011. [PDF] - 山口 明彦, 高松 淳, 小笠原司:
強化学習によるロボットの動作獲得のための基底関数に基づく行動空間生成手法DCOB ---実機多自由度ロボットの匍匐動作への適用---,
日本機械学会ロボティクス・メカトロニクス講演会2010 (ROBOMEC2010), 2P1-G10, 旭川, 2010年6月. [PDF] - Akihiko Yamaguchi, Jun Takamatsu, and Tsukasa Ogasawara:
Constructing Continuous Action Space from Basis Functions for Fast and Stable Reinforcement Learning,
in Proceedings of the 18th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN2009), pp.401-407, Toyama, Japan, 2009. [final-draft] - Akihiko Yamaguchi, Jun Takamatsu, and Tsukasa Ogasawara:
Constructing Action Set from Basis Functions for Reinforcement Learning of Robot Control,
in Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA2009), pp.2525-2532, Kobe, Japan, May, 2009. [final-draft] - 山口 明彦, 杉本 徳和, 川人 光男:
回避行動の再利用メカニズムを備えた強化学習手法と多関節ロボットの全身運動学習への応用,
日本ロボット学会誌, Vol.27, No.2, pp.209-220, 2009. [PDF]